
La Retrieval Augmented Generation (RAG) sta trasformando il panorama dei modelli linguistici di grandi dimensioni (LLM) migliorandone accuratezza, attualità e contesto. Scopriamo i benefici e le prospettive future della RAG, mettendo in luce il suo ruolo fondamentale nell’avanzamento dell’Intelligenza Artificiale (IA) e dell’elaborazione del linguaggio naturale (NLP).
Indice degli argomenti:
Cosa sono le Retrieval Augmented Generation
In termini semplici, la Retrieval Augmented Generation è un processo per migliorare l’accuratezza, l’attualità e il contesto dei grandi modelli linguistici (LLM) come GPT4. Gli LLM sono già addestrati su enormi quantità di dati pubblici, spesso in gran parte da Internet, per generare il loro output. La RAG può estendere queste capacità a dati privati e domini specifici, che si tratti di un intero settore oppure di una specifica azienda.
Le implementazioni RAG funzionano combinando un LLM pre-addestrato con una componente di recupero (retrieval) collegata a informazioni facilmente accessibili che si trovano in una “knowledge library”. Questa, a sua volta, viene trasferita al LLM per fornire una risposta in linguaggio naturale più informata e accurata con le informazioni attuali e rilevanti.
Tuttavia, i LLM hanno anche dei limiti, che ne ostacolano l’efficacia e l’affidabilità. Uno di questi limiti è la dipendenza esclusiva dai dati di addestramento, che possono essere incompleti, obsoleti o inaccurati. Inoltre, i LLM non sono in grado di integrare le informazioni provenienti da fonti esterne, che potrebbero essere più aggiornate, rilevanti e verificate. Questo significa che i LLM possono generare testi che sono coerenti e informativi, ma non necessariamente corretti o pertinenti.
Chi ha inventato la RAG
Per superare questi limiti, molti tech vendor e grandi aziende adottano tecniche di Retrieval Augmented Generation (RAG) per velocizzare l’addestramento dei modelli AI e renderne più accurato e pertinente l’output. Un articolo pubblicato nel 2020, intitolato “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, firmato dal Data Scientist inglese Patrick Lewis e da altri membri del team di ricerca sull’AI dell’allora Facebook (oggi Meta), ha acceso i riflettori per la prima volta su questo modello, che unisce di fatto la capacità generativa dei Large Language Model con quella di scovare e reperire informazioni e dati rilevanti per il training dei modelli statistici dell’AI provenienti da fonti esterne.
In questo modo, è possibile creare testi e documenti più completi, rilevanti, pertinenti rispetto al contesto, fondati su dati sempre aggiornati e specifici per l’ambito di business, migliorando la qualità generale dell’output.
Come funziona la Retrieval Augmented Generation
I sistemi RAG consentono ai LLM di fare riferimento a una fonte di conoscenza esterna autorevole al di fuori del dataset su cui sono stati addestrati, come i dati proprietari di un’azienda, senza necessità di essere riaddestrati e senza compromettere la sicurezza di tali dati.
Questa componente di recupero delle informazioni è il fulcro del funzionamento del RAG e della sua differenziazione rispetto ai LLM generalisti.
I chatbot e altre tecnologie basati sul NLP possono trarre enormi vantaggi dalla RAG.
Immaginate di avere un chatbot per il servizio clienti di un retailer e che un cliente chieda quando i suoi articoli verranno consegnati. Senza RAG, la risposta potrebbe essere una ripetizione generica delle indicazioni del sito web, secondo cui gli articoli vengono consegnati entro 3-5 giorni lavorativi. Con RAG, invece, il chatbot è in grado di estrapolare la cronologia delle conversazioni e dei dati del CRM di questo specifico cliente, per creare una risposta su misura che gli consenta di far sapere che un articolo è atteso per il giorno successivo, mentre l’altro arriverà tra tre giorni.

Vantaggi principali dell’utilizzo dei modelli RAG
L’utilizzo del framework Retrieval Augmented Generation comporta diversi vantaggi. Uno dei più importanti è la capacità di rendere i modelli più agili. Sebbene i LLM sembrino avere accesso a tutta la conoscenza del mondo, sono limitati in quanto i loro dati di formazione possono diventare rapidamente obsoleti. La RAG consente di utilizzare in un LLM dati volatili e sensibili al tempo. Di conseguenza, permette di aggiornare un modello nel momento in cui l’utente lo esige, anziché richiedere che venga interamente riaddestrato regolarmente con nuovi dati.
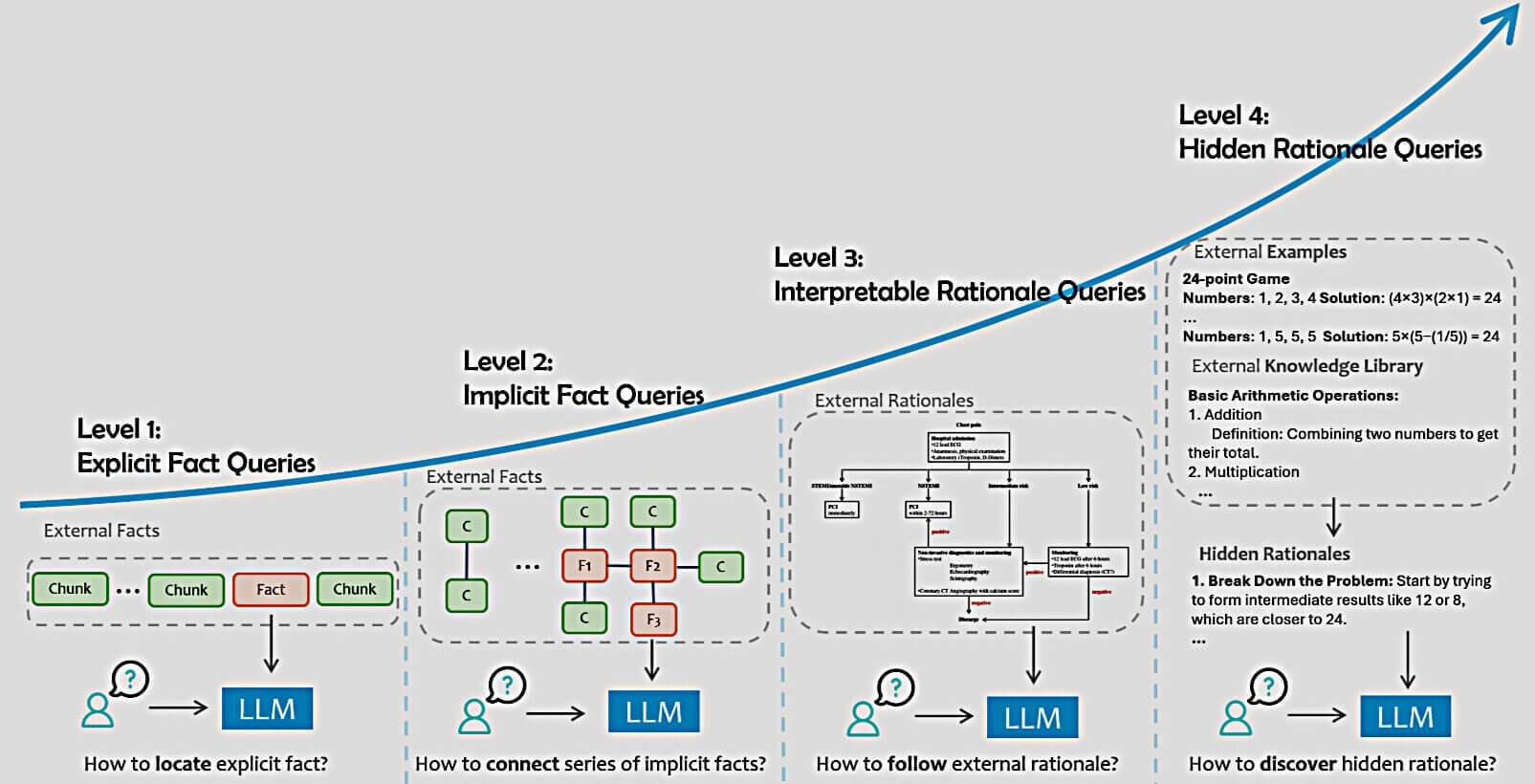
Fonte: Siyun Zhao , Yuqing Yang , ZilongWang, Zhiyuan He, Luna K. Qiu, Lili Qiu, Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely, Microsoft Research, 2024
La RAG può anche consentire di integrare il modello con dati sensibili che non possono essere utilizzati per l’addestramento iniziale del LLM. Per esempio, se pensiamo alle cartelle cliniche e alle storie mediche dei pazienti, queste contengono informazioni sensibili protette dalle normative sulla privacy. Anche se tali dati non verrebbero mai inclusi nell’addestramento iniziale dell’LLM, RAG può integrarli durante il runtime, consentendo a un operatore sanitario di effettuare query sui pazienti senza compromettere i loro dati. In questo modo, un’applicazione RAG è in grado di fornire risposte più accurate e contestuali a domande specifiche dei pazienti, migliorando la personalizzazione delle cure e il processo decisionale senza compromettere la privacy e la sicurezza dei dati.
Infine, RAG offre agli sviluppatori un controllo significativamente maggiore sulle loro applicazioni. Gli sviluppatori possono regolare e perfezionare il LLM per soddisfare esigenze e casi d’uso diversi. Sono anche in grado di limitare l’accesso alle informazioni sensibili e garantire che il modello fornisca le risposte pertinenti e giuste. Se il LLM fornisce risposte errate a una domanda, gli sviluppatori possono correggerle. In questo modo le organizzazioni riescono a utilizzare con fiducia le applicazioni di IA Generativa.
Applicazioni e casi d’uso della Retrieval Augmented Generation
La Retrieval-Augmented Generation è particolarmente utile per le applicazioni di IA Generativa che operano in contesti altamente specifici, come ad esempio la sanità, i servizi finanziari, la scienza e l’ingegneria.
In questi settori i dati tendono a essere sensibili e ci sono vari framework e regolamenti in vigore per salvaguardare la privacy. Ciò significa che i dati di addestramento sono spesso scarsi, rendendo la RAG essenziale per la creazione di applicazioni di IA Generativa utili in questi settori. Finora, l’adozione in questi settori è stata relativamente lenta e la mancanza di fiducia nella qualità delle risposte della Generative AI ne è la causa principale.
Sfide e limitazioni della RAG
Sebbene la RAG sia un approccio molto avanzato, la sua efficacia dipende dalla qualità del sistema di recupero e dei dati utilizzati. Se quest’ultimo non riesce a trovare documenti corretti o pertinenti, l’output generato può essere errato. Allo stesso modo, anche il database di recupero deve contenere documenti precisi, aggiornati e di alta qualità per garantire l’affidabilità delle risposte.
Attualmente si sta lavorando molto per ottimizzare il processo di recupero, concentrandosi sul rendere più fluida l’integrazione tra la knowledge source esterna e i modelli generativi. Nei prossimi anni si assisterà probabilmente a progressi che consentiranno ai modelli RAG di gestire query più complesse, migliorando le loro capacità di riconoscere il contesto e le sottili nuance dei dati a cui attingono.
RAG AI, il ruolo della Retrieval Augmented Generation nel futuro dell’intelligenza artificiale
La Retrieval-Augmented Generation sarà fondamentale per amplificare le capacità, la versatilità e l’affidabilità delle applicazioni di intelligenza artificiale, rendendola un’importante fonte di innovazione nel campo dell’IA e del NLP. A sua volta, è probabile che incoraggi ulteriori ricerche su modelli ibridi simili che combinano recupero e generazione. Potrebbe ispirare innovazioni nelle architetture dei modelli e nelle metodologie di addestramento che possano far emergere nuovi tipi di applicazioni di IA generativa.
Potremmo, inoltre, testimoniare lo sviluppo dell’IA Generativa in grado di intraprendere azioni basate su informazioni contestuali e suggerimenti dell’utente. Si tratta delle cosiddette applicazioni agenziali. Grazie alla comunicazione e alla comprensione avanzate, nonché al miglioramento del processo decisionale, le applicazioni agenziali RAG hanno il potenziale per offrire esperienze realmente personalizzate e azionabili. Immaginate un’applicazione con accesso al vostro calendario, alle vostre finanze, alla cronologia dei viaggi, ai programmi di fedeltà e alle vostre preferenze, in grado di negoziare e prenotare le migliori offerte per una vacanza da sogno, e di farlo come un local, in qualsiasi lingua e in base al vostro budget!
RAG LLM: una “iniezione” di accuratezza
Sebbene i sistemi RAG siano una potente aggiunta all’accuratezza di un LLM, è importante notare che questo approccio non elimina completamente i rischi di allucinazioni dell’Intelligenza Artificiale o di risposte imprecise.
È inoltre opportuno chiarire che i sistemi RAG, pur essendo in grado di attingere a fonti di informazione più aggiornate, non accedono alle informazioni da Internet in tempo reale. Al contrario, il RAG richiede dataset pre-indicizzati o database specifici che devono essere regolarmente aggiornati man mano che i dati si evolvono. Tuttavia, di solito è ancora molto più facile aggiornare questo database aggiuntivo che riaddestrare il foundational LLM.







